This week’s Linky is all about how quality is shaped by more than just code. It is shaped by incentives, boundaries, feedback loops, and how we respond when things go wrong.
🎧 No time to read? Check out the audio version, where I talk through this week’s links, connect the dots across them, and share practical takeaways you can use with your team.
Latest post from the Quality Engineering Newsletter
My final post on failure looks at why we struggle with it and what we can do about it.
My view is that by better understanding why failure feels so difficult, we can better equip ourselves to work with it. The takeaway is simple: failure does not feel nice when it happens, so we try to avoid it. What we need instead is to get more comfortable being uncomfortable, so we can understand what happened and learn from it.
While there is only so much you can do about a particular failure after the fact, you can improve your chances of it not happening again. Also, larger failures are often made up of lots of smaller failures. If we get better at spotting and correcting the smaller ones, we can dramatically reduce the chances of major ones occurring, while preserving confidence and self-esteem.
Coding was never the hard part
The hard part is figuring out what to build and understanding users well enough to know what they actually need. It’s selling an idea to skeptical stakeholders. It’s making good decisions with incomplete information. It’s maintaining momentum through the long middle of a project when the initial excitement has faded and the finish line isn’t yet visible.
If using agents to build software systems becomes the norm, the amount of code teams produce is going to increase significantly. That in turn increases the overhead of coordinating people’s actions, reviewing what is being produced, and deciding what should go out.
If our ways of working are not optimised for that increase, they will collapse under the weight of it all. The shift to agents could highlight who has been optimising for capability and sustainability, and who has been optimising for shipping speed alone. Via The K-Shaped Future of Software Engineering | X.com
If you don’t define the limits, someone else will
Testing in production is all good, but without guardrails you might not get what you wanted:
I sent Nick on a very simple mission. Walk a few metres from our flat, visit three local microbreweries, pick up a selection of cans for my brother in law’s birthday. We had dinner booked for 7pm. Clear objective. Low risk. What I failed to specify was scope control, sampling limits, or any form of governance. Nick quite reasonably decided he should try each drink first, just to make sure it was suitable. Thorough validation, you could say.
The post goes on to show that without defined boundaries, success criteria, and signals to stop, people will optimise for what makes sense to them, which might not align with your outcome.
Forgot the third stage: checking that it was actually the right thing to build
I came across this quote from Marty Cagan, where he only mentioned two stages for software projects:
what should you build
building it
*Marty popularised the idea of empowered, cross-functional product teams that use fast discovery to reduce risk and build products customers want
To me, it looked like he had missed the measurement stage, where you check whether it was actually the right thing to build. So I asked him on LinkedIn, and to my surprise, he replied.
His view was that checking after you have built it is too late. You need to know it is the right thing to build at stage one, which is what discovery is all about. So figuring out what to build is not just about generating ideas, it is also about proving they are worth building.
This is where an MVP and testing in production can be extremely useful. Once you have evidence that the feature or experience is valuable, you can then focus on building it right, so it is scalable, maintainable, and resilient. Via Forgot the third stage, Marty Cagan | Jitesh Gosai | LinkedIn
Intentional addictiveness, or an unintentional outcome?
The plaintiff (the person suing the tech companies) and her lawyers argue that social media companies intentionally designed their products to be addictive to children. They point to features like endless scroll, auto‑play, and beauty filters as design choices that prioritised engagement (and ad revenue) over children’s safety or well‑being.
This got me thinking.
Many modern software companies set OKRs focused on driving Daily Active Use (DAU) or engagement metrics (for example, how often people interact with a post). Engineering teams are then asked to find ways to move those numbers through new product features and experiences.
So could it be that the incentives set by leadership unintentionally lead teams to create features that are sticky? Features that keep users engaged and continuously push those metrics upward?
That stickiness can form habits, and any habit can become negative if it happens automatically. (How many times do you pick up your phone and check notifications without thinking? I am definitely working on that. 😄)
Some people have better impulse control than others, so for those who do not, these habits may become much harder to manage or avoid.
From a Quality Engineering perspective, quality is value to someone. That someone could be an end user who does not want an app to encourage habit-forming behaviour. So we may need to find a balance between:
quality attributes important to the business (expressed as OKRs), and
quality attributes important to users (such as less habitual or compulsive usage).
As QEs, we might even need to measure things that move in the opposite direction of what the business wants, which may not always be popular with leadership. Especially if your competitors are not doing the same, and that hurts your product in the short term. Via Social media addiction trials | Jacqueline Nesi | Substack
Testing doesn’t assure quality, provide confidence or prove quality
Note: shortened excerpt
If you claim that testing can assure quality, provide certainty, give “confidence”, you are also not helping. […] Testing aims to find problems that the stakeholders would want to know about, but we can’t ever prove that we have found all the problems that matter. […] As a tester, this is my service: I will help you find problems in a systemic, risk based manner, and I will tell stories about how I do this. I can do this together with other people, and help them become better at testing.
But I’m not in the confidence, assurance or quality business. Nope.
Testing provides information about the software system under test. That information can contribute to someone’s decision to ship, which may increase their confidence, but testing does not provide confidence itself.
Testing also cannot assure quality. It is feedback about how your system is performing. It does not change the system in a way that builds quality in. The people changing the system are usually the ones who can do that.
You could say the information testers reveal can influence how the system is built, but that is still not the same as assuring quality or building it in.
This is one reason testers and quality engineers are not the same role. Testers provide information about the system. QEs use what they learn about how quality is created, maintained, and lost in a socio-technical system to help engineering teams create the conditions for more of the quality outcomes we want, and less of the ones we do not.
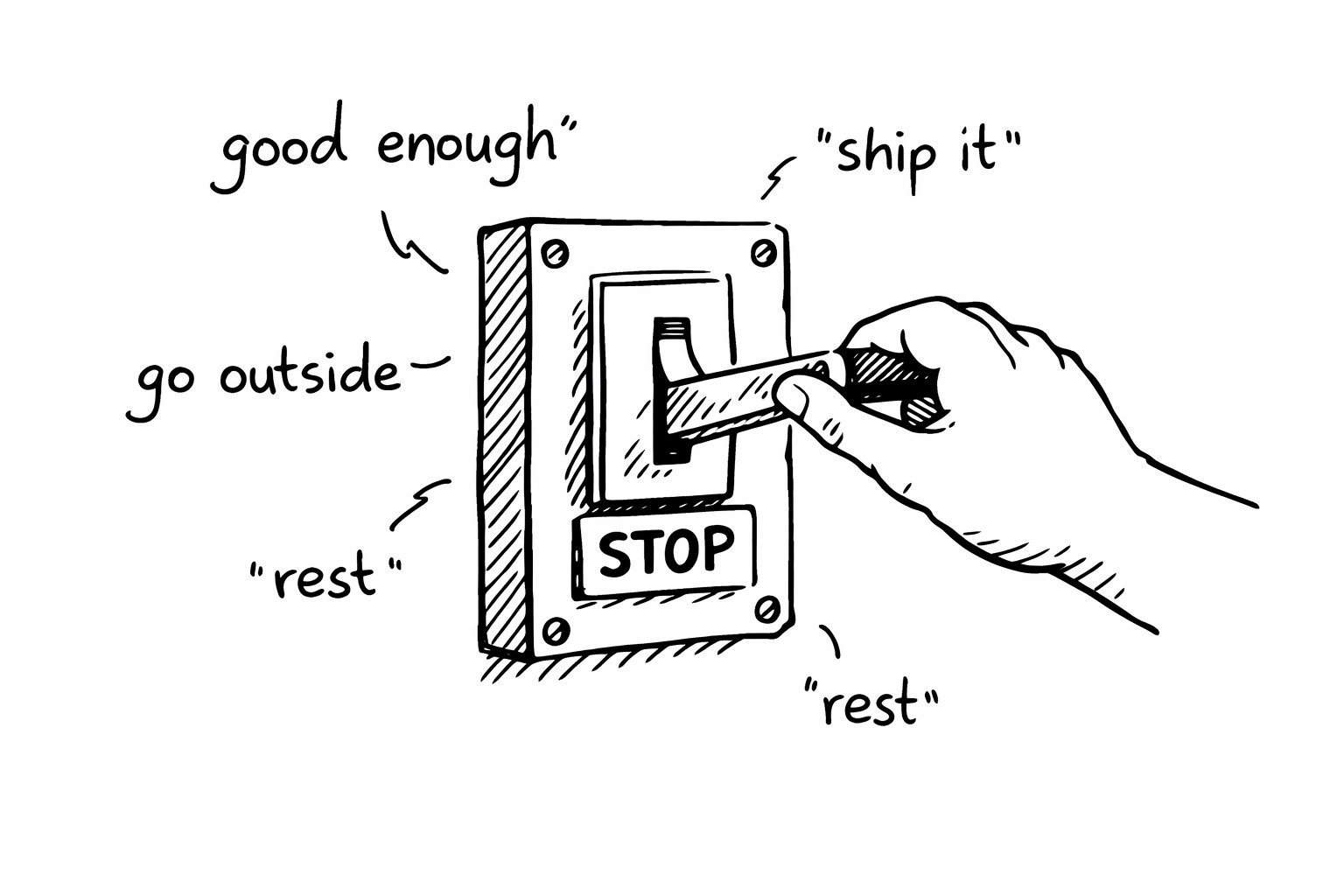
Here’s what I think the real skill of the AI era is. It’s not prompt engineering. It’s not knowing which model to use. It’s not having the perfect workflow. It’s knowing when to stop.
It is a long read, but well worth your time.
He is writing from the perspective of using AI to build software, and it burned him out. Not because the tools were bad, but because the constraint shifted. The bottleneck moved from writing code to reviewing code.
That review work is much more cognitively demanding than people expect. When you write code yourself, you review it as you go, so by the end you usually have a good sense of what you have built. With AI, you often need to review every single line, every single time, because it can subtly change things between prompts.
Over time, that can wear you down. The article is a really good reminder that scale without limits is not always a win. Via AI Fatigue is Real
This week’s links all point to the same thing: quality is rarely just about technique. It is shaped by boundaries, incentives, feedback loops, and how we respond when reality does not match our expectations.
This week’s Linky is all about learning in complex systems, and what gets in the way. Because we keep reaching for quick fixes (mindset shifts, root causes, other companies’ playbooks) and hoping for the best.
This week’s Linky is all about how teams define “good”, then build feedback loops to protect it. From Continuous Delivery principles, to quality strategy, to the messy reality of UI and human behaviour. Plus: I’m experimenting with an audio version of Linky, let me know if it’s useful.
This week’s Linky is about what makes change stick in engineering teams. Not better slogans or new role names, but social proof, visible work, and the conditions that make releasing feel normal.
Quality Engineering is more than software testing - It's about building quality into every part of software systems. Highly relevant for Quality Engineers, Testers, and Engineering Leaders. New issues every fortnight.
Quality Engineering is more than software testing - It's about building quality into every part of software systems. Highly relevant for Quality Engineers, Testers, and Engineering Leaders. New issues every fortnight.