
Can We Automate All the Things? Exploring the Limits of Testing in Software Systems
Can you automate all your testing? Well, it depends on how certain you are about your software system's behaviour.

If there is one thing I see most often across the software industry, it is the view that you can swap manual testing for automated testing while keeping all the upside of manual testing (feedback on how your product works) and removing all the downsides (slow, tedious, and requires people to do it).
Testing isn’t binary
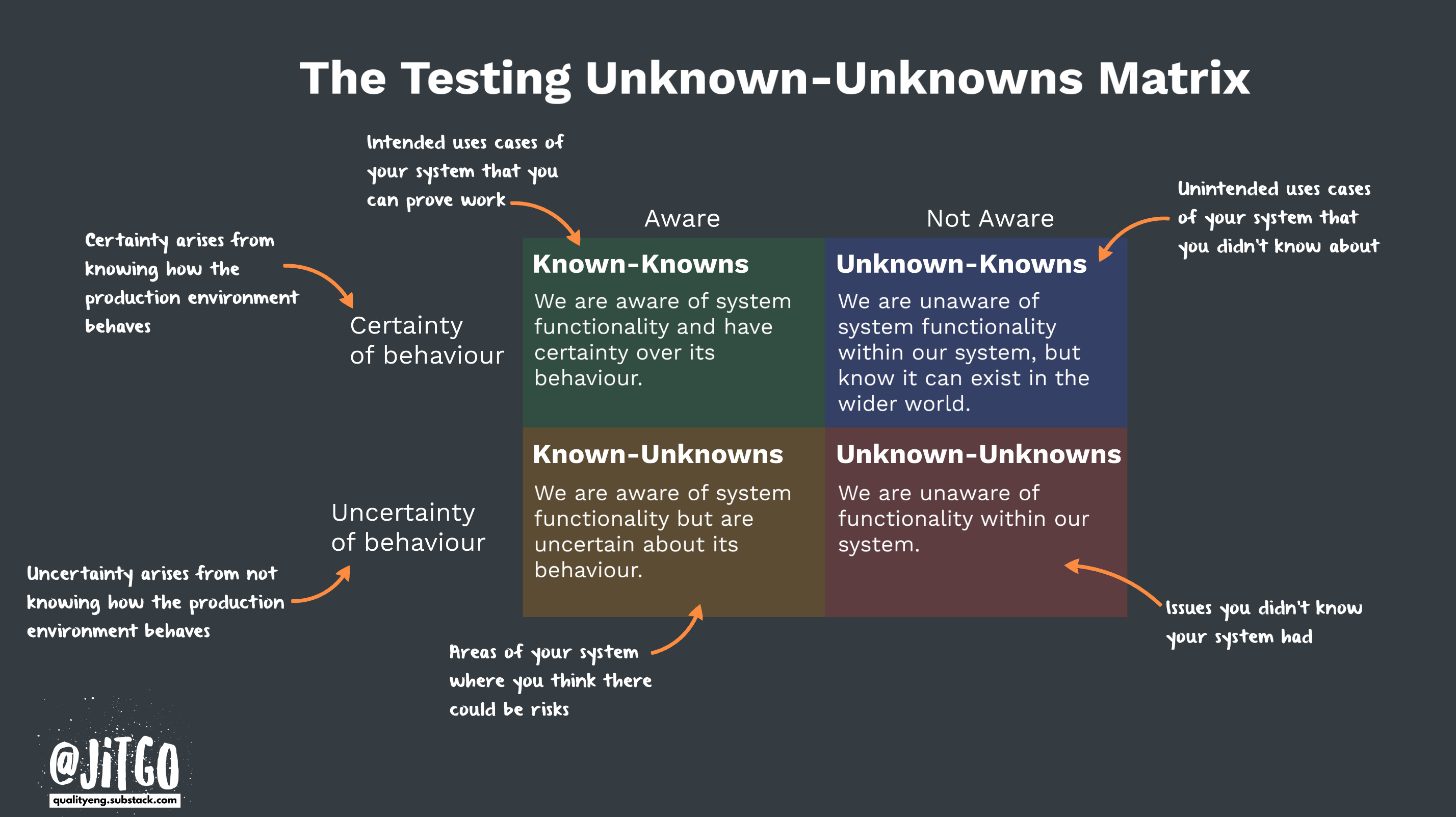
As mentioned in The Testing Unknown Unknowns, I feel this perspective comes from how we frame testing which is often in a very binary view of either something works as intended (a pass), or it doesn't (a fail). I think this limits our thinking that testing only has one purpose, and that purpose can be automated away. But for me, testing is all about feedback that helps us lower the uncertainty we have about how our software systems behave.
And if we reframe testing into the unknown-unknowns matrix we can better understand how it helps us to lower our uncertainty about the behaviour of our software systems, see image below.
Can you automate all your testing?
But we’re st…
Keep reading with a 7-day free trial
Subscribe to Quality Engineering Newsletter to keep reading this post and get 7 days of free access to the full post archives.